The Surprise Loop: What LLM Pre-Training Actually Does

Siddharth
June 14, 20266 min read
Ask a large language model how many r's are in "strawberry." Watch it flounder. That failure is not a bug. It is a direct artifact of the single most important design decision in modern AI — and understanding why it fails teaches you almost everything that matters about how these machines learn.
Every breakthrough in machine learning before 2017 had the same chokepoint: labels. ImageNet, the dataset that launched the deep-learning revolution, required 14 million human-annotated photographs. Someone had to look at each picture and tag it "golden retriever" or "speed limit sign." That is expensive, slow, and fundamentally unscalable.
For language, the problem looked even worse. There is no ImageNet for text because language is combinatorially explosive. The space of valid English sentences is effectively infinite. You cannot hire enough graduate students to label them all.
The insight that changed everything: text is self-labeling. Every next word in a corpus is the correct label for every word that came before it.
This is called self-supervised learning, and it is the reason you can train a model on trillions of words without paying a cent for human annotation. The text itself becomes the curriculum. Early words in a sentence are harder to predict (many valid continuations); later words are constrained by context. The difficulty gradient emerges naturally from the data.
Before a model can learn, raw text must be converted into numbers. The naïve approach — a dictionary where every word gets an ID — fails for two reasons. First, vocabulary size explodes. Second, the model has no way to handle words it has never seen.
The solution is subword tokenization (BPE, WordPiece). The algorithm compresses the corpus by iteratively merging the most frequent character pairs into new tokens. "Unhappiness" might become [un] [happiness]. "Strawberry" might become [straw] [berry]. Rare words decompose into known pieces; common words stay whole. The vocabulary stays small and manageable — usually 32,000 to 100,000 tokens.
But this elegant compression has a hidden cost. The model never sees individual letters. It sees opaque token IDs. When you ask it to count the r's in "strawberry," the token [straw] is an atomic object. The model has no internal representation of s-t-r-a-w as five distinct characters. It reasons about tokens, not letters.
This is not a flaw to be patched. It is an architectural trade-off made at the very beginning of the pipeline, and it propagates into every downstream behavior. The model is brilliant at predicting the next token. It is blind to the internal structure of the tokens themselves.
At the core of the model is a neural network that outputs raw numbers — logits — one for every token in the vocabulary. These logits are unbounded real numbers. They could be 4.2 or -17.3. They are not probabilities.
To turn them into a valid probability distribution, we pass them through the softmax function. Softmax does two things: it exponentiates every logit (which forces everything positive and amplifies differences), then it normalizes by the sum so the total probability mass equals exactly 1.0.
The result is a ranked list of guesses. For the prompt "The cat sat on the ___," the model might assign 38% to "mat," 21% to "floor," 9% to "couch," and vanishingly small probabilities to the other 49,997 tokens in the vocabulary. The vocabulary is the model's entire universe of possible next words.
Now comes the learning. We know the actual next token in the training corpus — it is right there in the text. The model predicted a probability distribution. We need a way to measure how badly that distribution missed the truth.
Enter cross-entropy loss. It measures how "surprised" the model is by the correct answer. If the model assigned 90% probability to the actual next token, its surprise is low. If it assigned 2%, its surprise is high. The math is elegant: take the negative logarithm of the predicted probability for the correct token. Low probability → high loss. High probability → low loss.
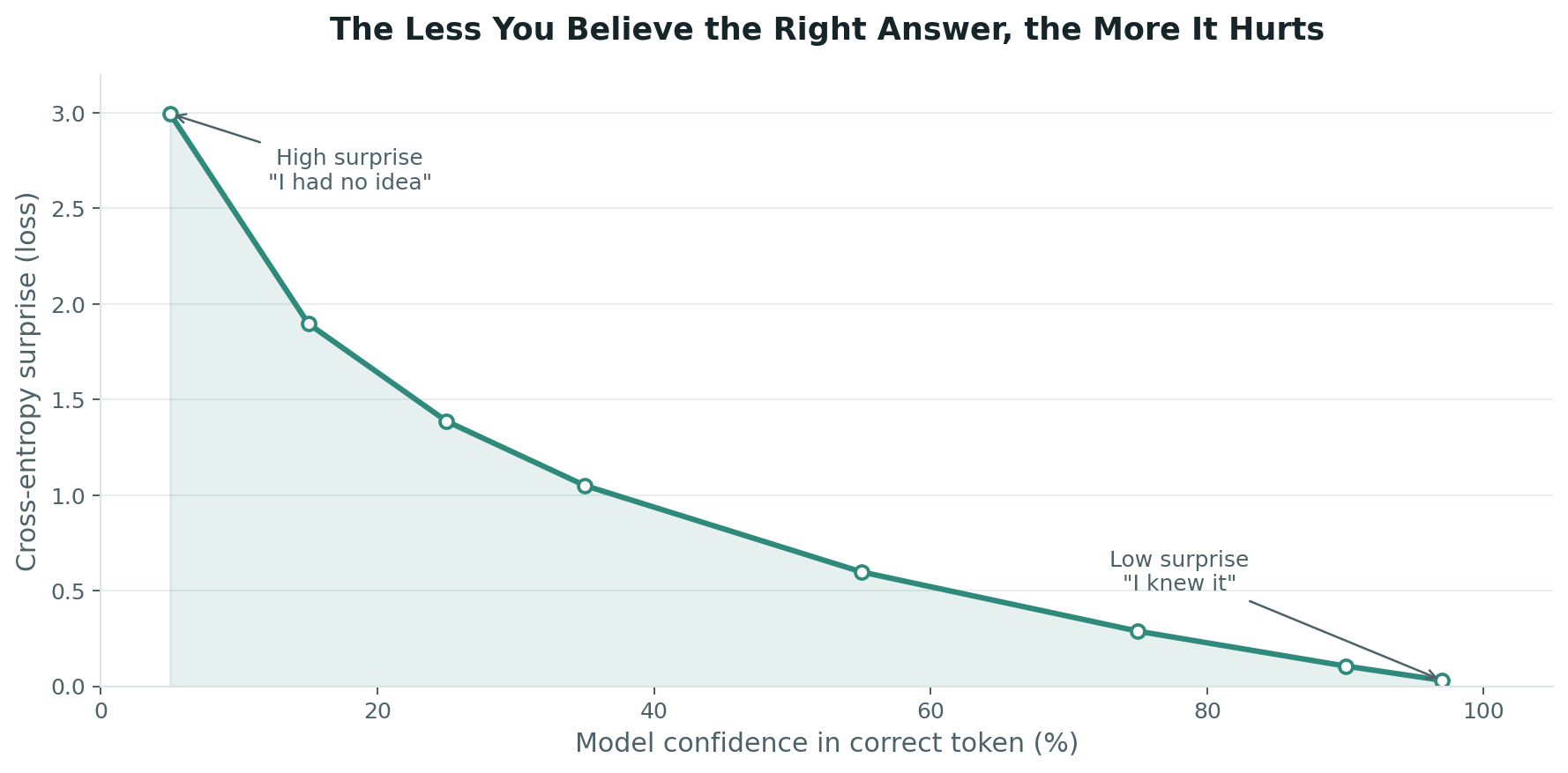
This loss value is the signal that drives everything. Through backpropagation, the gradient of the loss flows backward through every layer of the network, nudging billions of parameters — by fractions of a fraction — in the direction that would have produced a slightly better guess. Do this millions of times across trillions of tokens, and the model converges from random noise to something that sounds eerily human.
Every training step is the same closed loop: predict, measure surprise, correct, repeat.
Here is the subtlety most explanations miss. Training and generation are not the same process. They use the same machinery, but their goals are opposite.
During training, we want the model to minimize surprise. We want its probability distribution to peak sharply on the actual next token. We want it to converge, to become more certain, to learn the statistical truth of the training corpus.
During generation, we want controlled surprise. If the model always picks the single most likely next token, it becomes a boring automaton. It repeats safe, common phrases. It never says anything original. It is, in a real sense, too predictable to be interesting.
So we introduce two knobs:
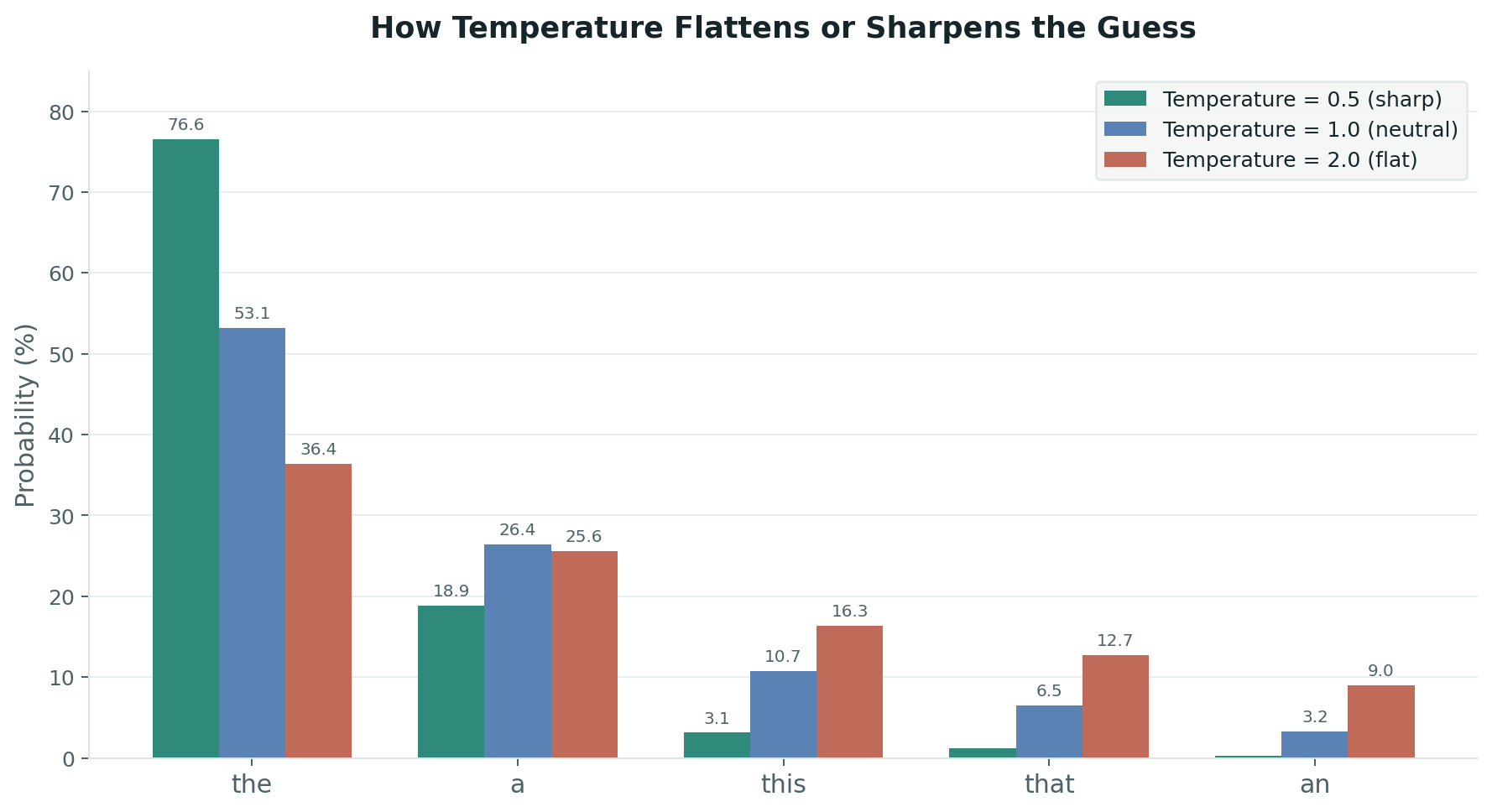
Training is about becoming less surprised. Generation is about being surprised just enough to stay interesting. The same model, the same weights, the same forward pass — but a completely different philosophy at the sampling layer.
Pull it all together and the pipeline is almost embarrassingly simple in structure, even if the scale is staggering:
The next time someone tells you that large language models "understand" language, remember the pipeline. They do not understand. They predict. They are statistical pattern-matching machines trained on a self-labeling curriculum of human text, optimized to minimize surprise, and sampled with just enough randomness to sound creative.
The strawberry failure is not a quirk. It is a direct consequence of tokenization. The hallucinations are not bugs. They are the model doing exactly what it was trained to do — predict the statistically most likely next token, even when the context demands something the training distribution never contained.
And the creativity? The moments where the model says something genuinely surprising and useful? That is not understanding either. It is the controlled noise of temperature and nucleus sampling, rolling dice in a high-dimensional probability space, occasionally landing on combinations no human wrote but that happen to work.
None of this diminishes the achievement. The fact that prediction-at-scale produces behavior this sophisticated is one of the most remarkable engineering feats of the century. But calling it understanding confuses the map for the territory. The model is a mirror — vast, distorted, and occasionally brilliant — trained to reflect the statistical shadows of everything humanity has written.
The model is a mirror — vast, distorted, and occasionally brilliant — trained to reflect the statistical shadows of everything humanity has written.
Know the pipeline, and you know both the power and the limits.
Thoughts and essays, published with Yokush. See more posts
 Siddharth11 min
Siddharth11 min Siddharth5 min
Siddharth5 min Siddharth13 min
Siddharth13 min
Comments 0