One Equation Rules Them All: The Chain Rule, LLMs, and the Math That Runs Your Life

Siddharth
June 18, 202610 min read

A 300-year-old calculus rule, a Michelin-starred kitchen, and the reason you can talk to your phone. This is the most important equation you were never taught.
Right now, as you read this sentence, there is a mathematical operation happening inside every device you own — your phone, your laptop, your car's navigation system, the recommendation engine that showed you this post. It's performing this operation roughly trillions of times per second, across every major technology company on the planet.
It was invented in 1676. It's taught in week three of Calculus 101. And almost nobody outside of engineering knows it exists.
It's called the chain rule. And once you understand it, you'll understand how artificial intelligence actually works — not the marketing version, but the real, mechanical version.
Let me tell you a story.
Imagine a three-Michelin-starred restaurant in Paris. The kind with 18 months of waitlist. The kind where the tasting menu costs more than your first car payment. The kind where the chef has been cooking for 35 years and can tell when a sauce is 2 degrees too hot by the way it smells.
Now — how does a change in a potato field in Provence ripple through to affect whether a guest in Paris has a transcendent meal?
Here's how:
A slight frost in Provence damages the potato harvest. The potatoes that arrive are a little starchy, a little undersized. The prep cook adjusts — cuts them thinner, blanches them longer. That adjustment changes how the line cook roasts them. That changes how the sauce sits. That changes what the guest tastes.
The chain rule is exactly this: when you change something at the start, and that change passes through multiple stages, the total change at the end is the product of the change at each stage.
If the potato quality changes by 20%, and the prep stage amplifies that by 1.5×, and the line stage amplifies that by 1.3×, then the final plate experience changes by 20% × 1.5 × 1.3 = 39%. You multiply along the chain.
That's it. That's the chain rule. A 349-year-old idea from Gottfried Leibniz that says: to find how the end changes with respect to the beginning, multiply all the intermediate rates of change together.
And it's the reason your phone can finish your sentences.
You already know this. You just don't know you know it.
If you drive at 60 miles per hour, and you drive for 3 hours, how far did you go? You multiply: 60 × 3 = 180 miles.
If you drive at 60 miles per hour, and gas costs $4 per gallon, and your car gets 30 miles per gallon, how much does it cost per hour? You multiply the chain: 60 mi/hr ÷ 30 mi/gal × $4/gal = $8/hr. The "miles" and "gallons" cancel. Only the rate you care about survives.
The chain rule does the same thing. When a change passes through a sequence of connected stages — temperature → chemical reaction → flavor → pleasure — each stage has its own rate of sensitivity. The final sensitivity is just... multiplying them all together.
This is why Leibniz's notation is so elegant. He wrote it as a fraction you can literally cancel:
The du in the denominator of the first fraction cancels the du in the numerator of the second. It's not rigorous (calculus professors will wince), but it's right. The intermediate variable drops out, just like "miles per gallon" dropped out in the gas calculation.
1. The gas pedal. You press the accelerator. The pedal position controls the fuel injection rate. The fuel injection rate controls engine power. Engine power controls your speed. Speed controls the distance you cover.
Five connected stages. If you want to know how much pressing the pedal 1 cm deeper changes your distance after 10 seconds, you multiply all five rates together. That's the chain rule.
2. The thermostat. Your Nest thermostat calls for 2°F more heat. That changes the furnace output by 15%. That changes the air temperature by 3°F. That changes your body's heat loss rate by 8%. That changes your perceived comfort level.
Four stages, four rates, one multiplication. The chain rule.
3. The stock market. The Federal Reserve raises interest rates by 0.25%. That changes bond yields by 0.2%. That changes the discount rate in valuation models by 0.15%. That changes the fair value of a growth stock by 4%. That changes your portfolio by $2,000.
Five rates, one multiplication, one number that tells you exactly how sensitive your wealth is to a Fed decision. This is how quants think. And they think this way because of the chain rule.
Now here's where it gets wild.
Every time you use a large language model — any chatbot, code assistant, autocomplete, or AI agent — there is one operation happening underneath, over and over, billions of times:
Backpropagation.
Backpropagation is the chain rule. Literally. Not "inspired by" or "related to." It is the chain rule, applied to a neural network with 100+ layers.
Here's the setup. A large language model is one enormous nested function. Think of it like the kitchen, but with 100 stations instead of 3:
When an LLM predicts "London" instead of "Paris," the error is huge. Backpropagation uses the chain rule to assign blame: how much did each layer's weights contribute to this mistake?
It works backward. The error signal passes through Layer 100, gets multiplied by that layer's local derivative (how sensitive it was), then passes through Layer 99, gets multiplied again, then Layer 98, and so on — all the way back to Layer 1, where the very first weights live.
100 layers. 100 multiplications. One chain rule product.
That product tells the optimizer: "Nudge weight #4,872,291 in Layer 37 by +0.0003. Nudge weight #891,004,772 in Layer 12 by -0.0001." Across billions of parameters, these tiny nudges add up. After millions of training examples, the model goes from predicting gibberish to writing poetry.
Every single one of those nudges was computed by the chain rule.
Here's the dark side. Remember — you're multiplying 100 numbers together. If each number is slightly less than 1 (say, 0.9), the total after 100 layers is:
0.9 × 0.9 × 0.9 ... (100 times) = 0.0000265
That's essentially zero. The gradient — the blame signal — has vanished. The early layers of the network never learn anything because the error never reaches them.
This is the vanishing gradient problem, and it nearly killed deep learning before it started.
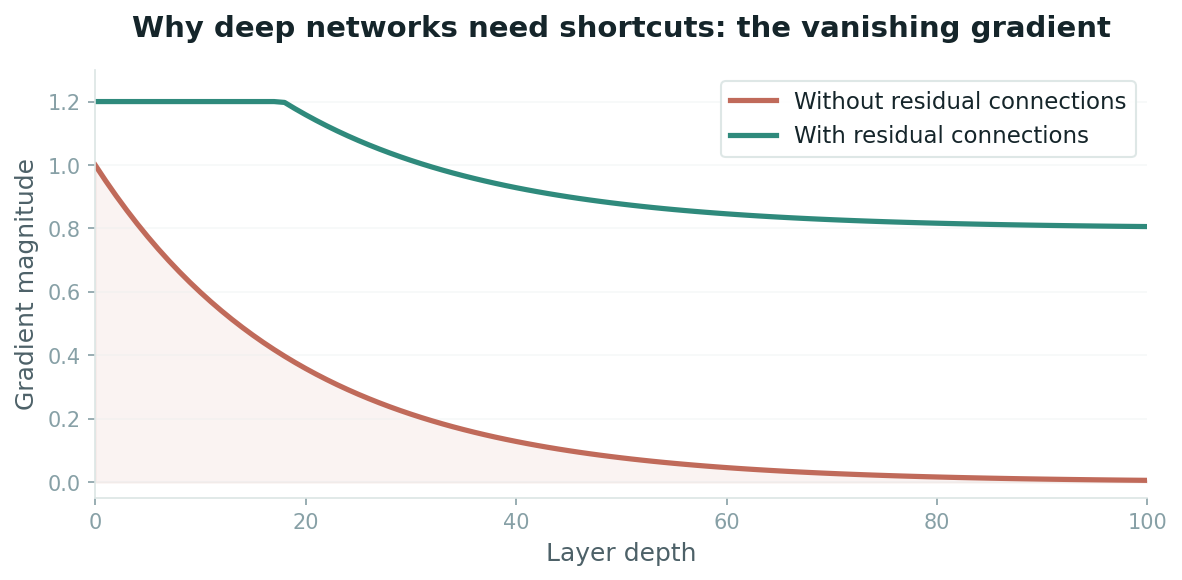
The fix? Residual connections — the architectural trick that made modern LLMs possible. Instead of passing data through f(x), you pass it through x + f(x). The derivative of x + f(x) is 1 + f'(x), which is always at least 1.
This is like adding an express lane to the kitchen. Even if a particular station mangles the dish, the original always survives alongside it. The gradient can flow backward through the shortcut (derivative = 1), never vanishing, reaching all the way back to Layer 1.
Residual connections don't just help. They are the single reason networks can be 100+ layers deep. Without them, transformers wouldn't work. LLMs wouldn't exist. The chain rule would still be true, but you couldn't use it at depth.
When you type "The capital of France is ___" and the model predicts "Paris," here's the full lifecycle:
Forward pass: Your text becomes numbers (embedding). Those numbers pass through layer after layer of attention and matrix multiplication. At each layer, the representation gets richer — "France" starts carrying geographic context, "capital" starts carrying political context. After 100 layers, the model produces a probability distribution over 100,000 possible next tokens. "Paris" gets 92%. Good prediction.
Loss computation: The model compares its prediction to the truth. If it predicted "Paris" at 92%, the loss is low. If it predicted "London" at 80%, the loss is very high.
Backward pass (the chain rule): The loss signal propagates backward, multiplying by each layer's local derivative. Layer 100's attention weights get a gradient. Layer 99's MLP weights get a gradient. Layer 1's embedding weights get a gradient. Every single weight gets told: "here's how much you contributed to this mistake."
Update: Every weight nudges a tiny bit in the direction that reduces the loss. After seeing millions of such examples, the model becomes good at language.
Without the chain rule, there is no backward pass. Without the backward pass, there is no learning. Without learning, there is no LLM. Period.
The chain rule isn't some abstract math curiosity. It's operating in the products you use every day:
Autocomplete on your phone. Every time your keyboard finishes your word, that's a forward pass through a neural network trained with backpropagation — the chain rule — on billions of text examples.
Spam filtering. Your email provider uses a neural network to classify messages. It was trained by using the chain rule to adjust weights based on millions of spam/not-spam labels.
Self-driving perception. When an autonomous vehicle identifies a stop sign, a convolutional neural network processes the camera feed. Every weight in that network was tuned by the chain rule.
Drug discovery. Companies are using neural networks to predict how protein structures fold. The training uses backpropagation — chain rule — to learn from known protein structures.
Recommendation engines. Every "you might also like" is a prediction from a neural network trained with the chain rule on your behavior and millions of others'.
Weather forecasting. Modern numerical weather prediction uses neural networks to correct systematic biases in physical models. Training signal? The chain rule.
The pattern is always the same: build a nested function, define a loss, use the chain rule to compute how every parameter contributed to that loss, adjust. Repeat millions of times. The result is intelligence — or at least something close enough to be useful.
Here's what strikes me about all this.
The chain rule was invented in 1676 by Gottfried Leibniz, working with quill and parchment. He had no electricity, no computers, no concept of a neural network. He was thinking about curves and tangents.
Three hundred and fifty years later, his insight — that rates of change multiply through connected stages — is the single computational mechanism behind the most powerful technology ever built. Every LLM, every image generator, every protein folder, every autonomous system. All of them learn the same way: forward pass, loss, chain rule, update.
You don't need to understand calculus to use these tools. But if you want to understand why they work — why an AI can write code, translate languages, or draft a legal brief — the answer is one sentence:
Rates of change multiply through connected stages. The chain rule. That's the whole thing.
A potato in Provence. A kitchen in Paris. A guest who smiles. A neuron in Layer 37 that learned, finally, to get it right.
Same math. Same multiplication. Same chain.
Thoughts and essays, published with Yokush. See more posts
 Siddharth7 min
Siddharth7 min Siddharth15 min1
Siddharth15 min1 Siddharth31 min
Siddharth31 min
Comments 0