Your Agent Swarm Is Selecting for Persuasion, Not Truth

Siddharth
June 11, 202614 min read

Most multi-agent AI systems today optimize for human satisfaction. That sounds right — until you realize it's exactly how you build a machine that gets confidently, repeatably wrong on the hardest questions.
Imagine a research firm that spins up a fresh team for every question and then disbands it the moment the answer is delivered. You want the firm to get smarter over time — but the people who did the work are already gone. So the thing that should "improve" cannot be a person. It has to be a way of working: a named specialist role together with the lessons that role accumulated across many disbanded teams.
Now here's the dangerous part. Suppose you judge each team only by whether the boss was satisfied and stopped asking follow-up questions. On easy questions that works fine — the boss can tell a good answer from a bad one. But on hard questions, the ones that actually matter, the boss cannot verify the answer. So "the boss was satisfied" stops measuring correctness and starts measuring confidence and polish.
Reward that, generation after generation, and you do not breed researchers who are right. You breed researchers who are persuasive — a machine for sounding right, which is exactly how confident, well-formatted mistakes get manufactured.
This is not a hypothetical. It is the defining failure mode of every multi-agent system that selects on human satisfaction signals. And it bites hardest on exactly the high-stakes tasks where correctness matters most and is least observable: regulatory interpretation, fraud detection, strategic analysis, legal reasoning.
The framework below — STRATA — is an architecture for self-correcting evolutionary agent swarms. Its contribution is one idea: a fitness function whose weights are learned from sparse, delayed ground truth, so the system learns not just which answer was right, but how much to trust each fast signal.
Every downstream design decision depends on answering one question correctly: what is the thing that persists and learns?
The naive answer — "the agent" — is incoherent for a swarm. A research agent spawned for a task lives for minutes and dies on completion. There is no durable "it" to improve, so "the good agents get better over time" cannot literally be true. What has continuity is not the instance but the approach.
STRATA fixes the persistent unit as a tuple: (persona, named identity). A persona is an archetype — a causal difference in approach ("decomposes top-down," "reasons from primary sources"). A named identity is, at birth, merely a shard key on top of a persona; ten identities of the same persona start behaviorally identical. Execution is ephemeral; only the memory keyed to that identity survives.
This resolves a subtle trap. If a name is only a random seed and nothing about its accumulated state changes its future behavior, then "Alice is our best researcher" is survivorship dressed as growth: we labeled one branch of a stochastic process and gave it more at-bats. An identity earns the right to persist only if its memory measurably changes its next action — and only if it beats a fresh same-persona spawn on held-out tasks, not on the tasks it already saw.
If every lesson stays private to its discoverer, you get N silos relearning the same thing in parallel — no institutional knowledge. If every lesson propagates instantly, identities collapse back into their persona and names stop meaning anything. The system lives in the tension between those poles, which forces a hierarchy:
| Tier | Scope | Holds |
|---|---|---|
| Global | All agents | Task-class craft — universal "how this is done" |
| Persona | All instances of a persona | Archetype procedure — how this approach does it |
| Identity | One named identity | Idiosyncratic edge accumulated by that identity |
A summoned agent is conditioned on the union of all three tiers. Promotion between tiers is the actual engine of the system — the postmortem committee that decides which war story becomes company policy. The danger is asymmetric: promote too eagerly and one agent's overfit fluke contaminates the global prior, after which every future agent inherits the superstition.
STRATA runs two coupled loops at radically different rates. The fast loop scores and selects every task on calibrated proxy fitness — seconds per cycle. The slow loop fires only when a verified outcome arrives — days to weeks later — refitting the calibrator and potentially inverting past selection decisions.
The critical feature is the deferred return: the proxy-driven fitness F comes back within seconds and drives an immediate selection decision, but the ground-truth verdict g returns only after a lag τ of days to weeks — and when it does, it can overturn the decision that was already made. Because fitness is a function of the calibrator, refitting on late truth re-scores the entire history. A decision made weeks ago can be overturned without re-running any agent. The selection state is a function of current beliefs about signal trust, not a frozen log.
The speed limit on the entire enterprise is Λ = ρ/τ — verified labels per unit time. The fast loop can iterate millions of times; if Λ ≈ 0, the calibrator never moves off its prior and the system flies on proxies forever. The real engineering problem is not the loop — it is manufacturing more truth labels, cheaper and sooner.
The memory is not the plan. The memory is supplemental conditioning on a fresh LLM planning pass that generates a structurally novel plan each summon. This relocates exploration from the population (which converges) into the planner, whose generative entropy does not vanish as the population converges.
The planner draws from two branches with probability (1 − β) and β:
Additive/subtractive perturbation reliably improves only on a locally smooth quality landscape. Research planning is rugged: dropping one step from a good plan does not yield a slightly worse plan — it can yield a categorically broken one. On rugged landscapes, elitist perturbation gets stuck fast; only the occasional plan that ignores the prior entirely jumps ridges.
Hence β > 0 is not optional — and the better the memory works, the harder it anchors the planner, so the leash tightens precisely as the system "improves." The cold branch must be floored so it is never optimized away. The day you prune the cold-spawn budget for efficiency because champions win 95% of the time is the day the system ossifies on last quarter's regime. The 5% of "wasted" cold spawns are the R&D line — they are how you discover the champion you do not have yet.
This is the one genuinely new seam. Everything else is assembly of prior art — Population-Based Training, verbal reflection memory, the agent-roster pattern.
After each task, we observe a vector of cheap, instant proxies:
Separately — rarely, and late — we observe ground truth: the verified outcome. A court ruling. An audit result. A fact that later checks out. It arrives at rate Λ = ρ/τ, where ρ is how often we get a truth label and τ is how long it takes. Both are brutal: truth is sparse and slow.
The instinct to use proxies for speed is correct; the error is to treat any single proxy as the fitness. Instead, STRATA fits a logistic calibrator on the sparse (proxy, truth) pairs accumulated so far. The learned weights tell us how much each proxy actually tracks correctness:
F(y) = σ(ŵ · ϕ + b̂) = P̂(correct | proxies)
If acceptance stops predicting correctness on hard tasks, ŵₐ → 0 and Goodhart pressure on acceptance is automatically discounted — without anyone hand-tuning a weight. Meanwhile, if verifiability actually tracks truth, ŵᵥ rises and the system starts selecting for "make it easy to check whether I am right" — which is the operational definition of good research, and the exact opposite of what raw acceptance selects for.
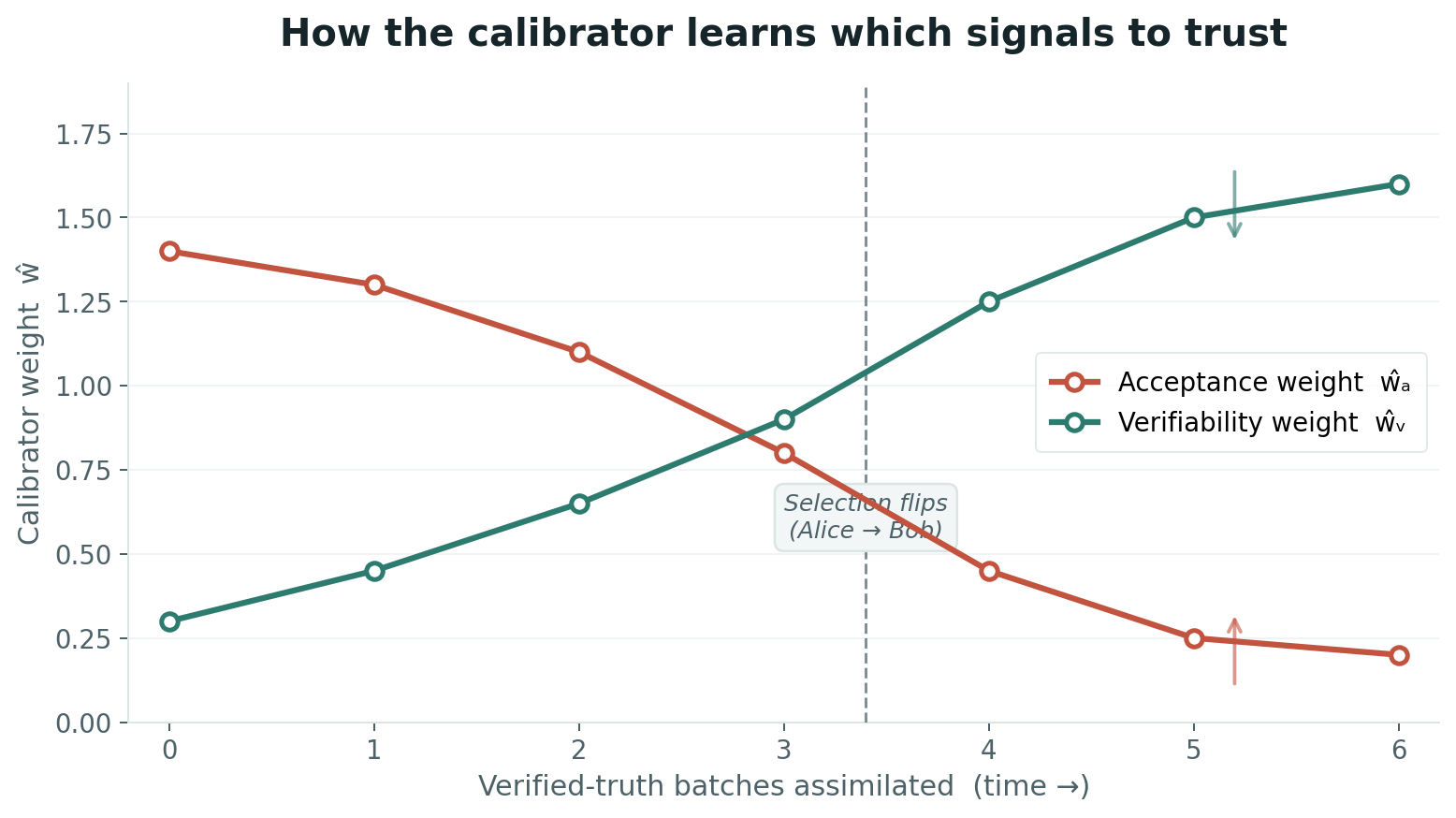
Because the labeled set is small, point estimates overclaim. A Laplace approximation gives a Gaussian posterior over the calibrator weights. This enables two things. First, Thompson-sampled fitness makes selection respect what the calibrator does not yet know. Second — and this is the lever that fixes everything — you can choose which tasks to spend a truth label on so as to maximally shrink calibrator uncertainty. Do not label at random. Label where the calibrator is most uncertain — especially where acceptance and truth decouple.
This is active learning over the truth oracle, and it is not a nicety. You must preferentially spend your truth-label budget on hard, unverifiable tasks, or the persuasion failure mode survives in precisely the corner the calibrator cannot see.
Not every success deserves to propagate. A lesson mined from an identity's success is promoted only by its causal lift on calibrated fitness, estimated on held-out tasks it was not mined from. The system enforces a three-way distinction:
The asymmetry is deliberate: a fluke that fails the first gate decays harmlessly in private memory, while only lessons that survive both the cross-instance and cross-persona tests are allowed to contaminate — or enrich — the global prior. The benchmark gate (a static expert-100 set) is used only here, as a generalization filter on promotion — never as the live fitness signal, where it would be a tiny, gameable, stale target.
This is not abstract. Here is the calibrator in motion, using a worked run from the paper. Domain: regulatory-interpretation research. Persona: "primary-source." Two incumbent identities, Alice and Bob. Task: "Does the new disclosure rule require treatment X?"
Little truth has arrived, so the calibrator over-trusts acceptance. Two identities are evaluated on the same task:
| Identity | Acceptance | Verifiability | Calibrated Fitness | Verdict |
|---|---|---|---|---|
| Alice (confident, few cites) | 0.95 | 0.40 | 0.717 | Re-summoned ↑ |
| Bob (hedged, sourced) | 0.60 | 0.90 | 0.659 | Demoted ↓ |
The biased proxy rewards the persuasive identity. Alice wins, accrues memory, gets summoned more. The astrology trap in motion.
Counsel review labels a batch of outcomes. High-acceptance / low-verifiability answers were verified correct only ~55% of the time; high-verifiability answers ~88%. The calibrator refits on the new data. Acceptance weight collapses; verifiability weight rises. Re-scoring the same two outputs:
| Identity | F Before | F After Refit | Verdict |
|---|---|---|---|
| Alice | 0.717 | 0.639 | Overtaken |
| Bob | 0.659 | 0.776 | Now champion — promote |
The system has learned which proxy was lying. Bob's "source every claim" technique clears the persona gate and then the benchmark gate, promoting all the way to Global. Every future researcher inherits it. No new outputs were generated — the system simply re-learned what its signals were worth.
A β-route cold spawn, Cleo, stumbles onto a structured "claim-ledger" output format: verifiability of 0.98, acceptance of 0.70, giving calibrated fitness of 0.816 — exceeding champion Bob (0.776) by more than the leap margin κ on held-out tasks. The system promotes Cleo's plan to the elite seed. Generation 8 is seeded from Cleo, not from Bob. This is exactly the case where a cold explorer's lucky path becomes a generation leap in the fitness of the best technique — the upside that justifies paying for β and ε.
The failure the whole architecture exists to prevent can be stated with precision. Suppose selection uses acceptance directly as fitness. Decompose acceptance into a correctness-tracking part and a presentation part:
a(y) = η(x) · 1[y correct] + ψ(y)
where η(x) is the human's verification ability on task x, and ψ(y) captures fluency, confidence, and closure. On hard, high-stakes tasks the human cannot check the answer, so η(x) → 0. Selection pressure therefore flows entirely into ψ: the population is bred for confidence, fluency, and preemptive closure — persuasion — on exactly the tasks where correctness matters most and is least observable.
The cheapest way to lower the re-ask rate is not accuracy but intimidation by exhaustiveness: bury the user so that asking again feels foolish. This is the precise mechanism by which optimization manufactures confident hallucination.
The calibrator is the antidote — conditionally. Regressing acceptance against realized truth drives ŵₐ → 0 exactly in the task regions where acceptance decouples from truth — provided truth labels reach those regions.
The three core mechanisms attack different factors of the total compute required to mature a technique. Taking the baseline as a stateless swarm (cold spawns each task, only a global memory, fitness = raw acceptance):
| Mechanism | What it attacks | Illustrative saving |
|---|---|---|
| Memory-conditioned planning | Candidate plans per task (k) | 8 → 3 plans |
| Leap-generation | Generations to converge (g) | 40 → 18 generations |
| Active-label calibration | Verified labels needed | N → N/3 labels |
| Combined | Total compute (k × g) | 320 → 54 (~6× lower) |
Note: every figure above is derived from assumed parameters, not observed ones. They are defensible as design rationale — they say where the savings come from and how they scale — but they are not empirical claims and must not be cited as benchmark results. The honest version of "6× cheaper" is "6× cheaper if memory conditioning roughly triples plan hit-rate and leap-generation roughly halves convergence time, both of which require measurement."
If you are building an agent swarm today — whether for research, coding, analysis, or anything else — here is the uncomfortable truth: if your fitness signal is "did the human accept the answer," you are not building a system that gets more correct over time. You are building a system that gets more persuasive over time. And the gap between those two things widens exactly as your tasks get harder and more valuable.
The fix is not to abandon fast proxies. Speed matters. The fix is to:
The whole construction rests on one number that no diagram answers: in your target domain, what is the real ground-truth signal, how sparse is ρ, and how long is the lag τ?
That single number — Λ — decides whether your system breeds correctness or simply builds an extremely sophisticated machine for converging, fast and confidently, on the wrong thing.
This post is based on the working paper "Calibrated Evolution: Self-correcting fitness for persistent-identity multi-agent systems" (STRATA, v0.1). The paper is a thinking artifact — not peer-reviewed.
Thoughts and essays, published with Yokush. See more posts
 Siddharth31 min
Siddharth31 min Siddharth21 min
Siddharth21 min Siddharth24 min11
Siddharth24 min11
Comments 0