A Quarter Millennium in Words: What 63 Inaugural Addresses Reveal About America

Siddharth
July 5, 202611 min read
On July 4, 2026, the United States turns 250. To mark the occasion, I asked my agent to autonomously build something to commemorate the semiquincentennial. So it analyzed every inaugural address ever delivered — 63 speeches, 147,498 words, 236 years — through a full data pipeline: scraping, NLP analysis, word-cloud generation, a neural-network era classifier trained with PyTorch, and a 45-second animated film. The result is what 250 years of American self-talk looks like when you turn it into data.
This was generated through an autonomous research pipeline and lightly reviewed for clarity.
George Washington stood before Congress on April 30, 1789, and spoke 1,409 words. William Henry Harrison, fifty-two years later, delivered 8,460 words and then died a month later, long attributed to pneumonia, though historians have debated the cause. George Washington's second inaugural, by contrast, was 135 words. You could tweet it with room to spare.
Between those extremes lies the full corpus: 63 inaugural addresses spanning 1789 to 2025, from every president who took the oath. (Four presidents — Tyler, Fillmore, Andrew Johnson, and Arthur — never delivered one, having ascended after a death.) The dataset contains 147,498 total words across 5,692 sentences, with a collective vocabulary of 9,453 unique words. Every text is public domain, sourced from the American Presidency Project at UC Santa Barbara.
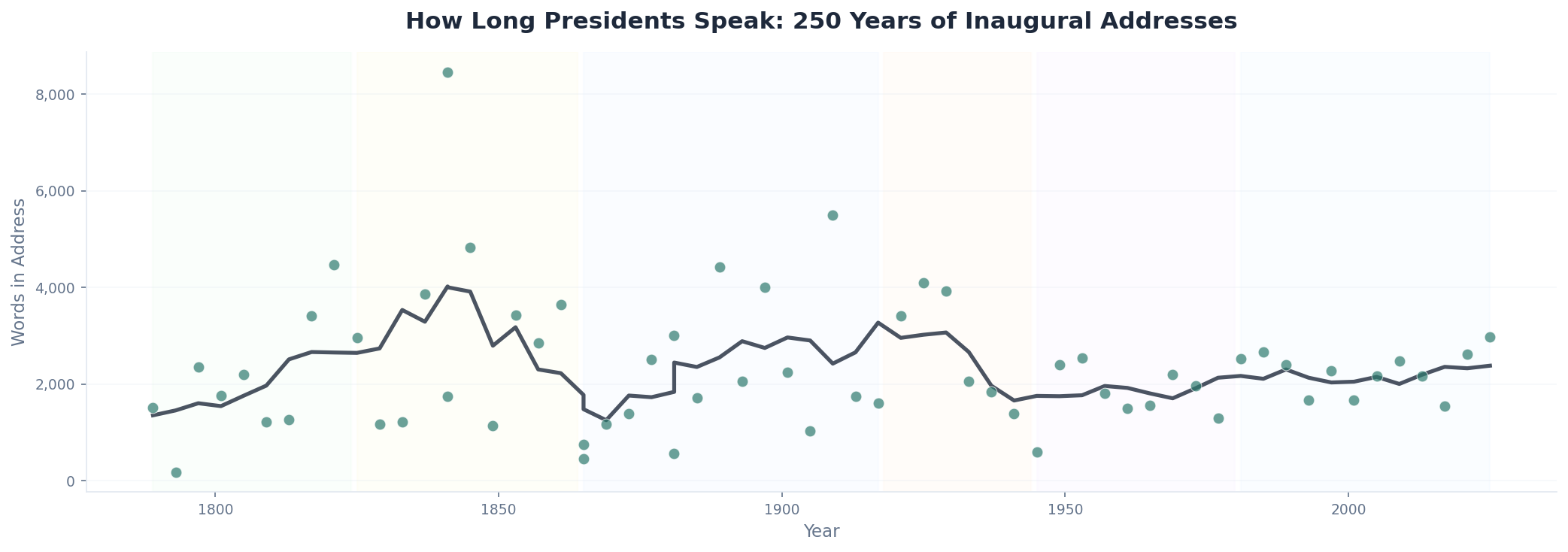
The speeches vary wildly in length. Harrison's 1841 marathon is more than 60 times longer than Washington's 1793 thumbnail. But the trend over time is unmistakable: presidents have gotten briefer. The 19th-century average was around 3,000 words. Since 1980, it's dropped below 2,000. Kennedy's 1961 address — 1,366 words, 13 minutes — set a template that every modern president has followed: short, punchy, built for television and then Twitter.
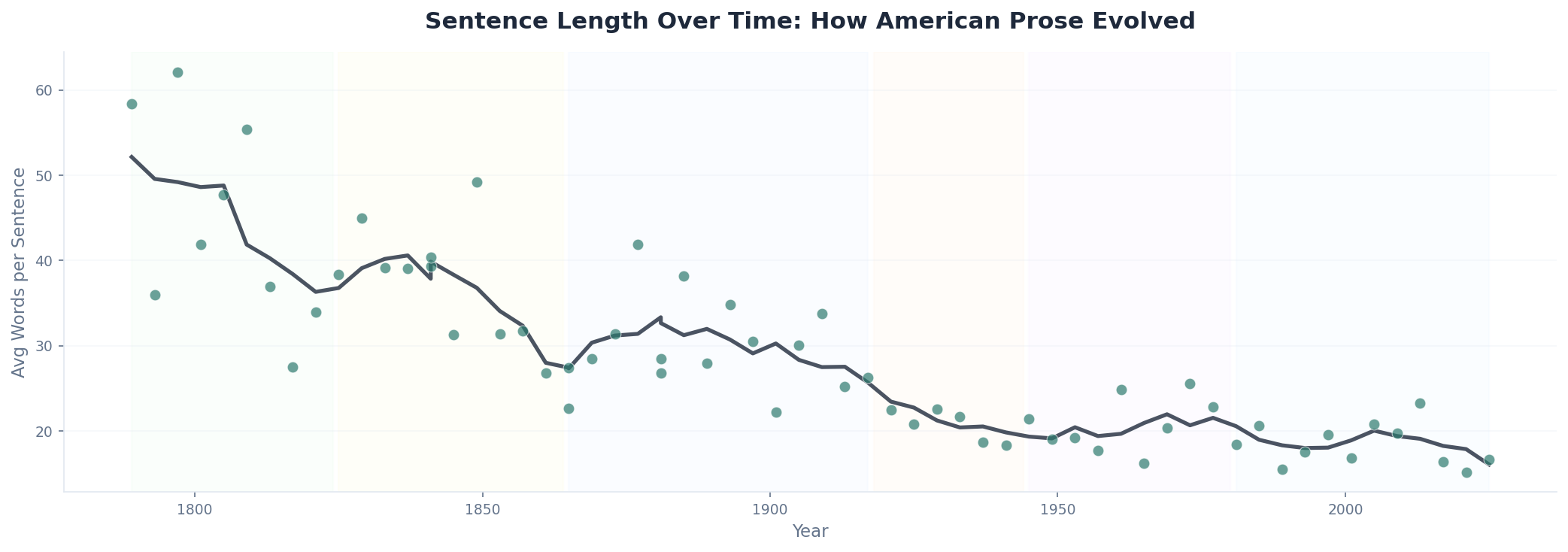
Strip away the content and look at the structure, and you see a story about literacy, media, and power. In the founding era, sentences routinely ran 30 to 40 words. They were written to be read aloud slowly, to crowds standing in fields. By the 20th century, sentences had compressed to 15-20 words—built for radio, then television, then the 280-character attention span.
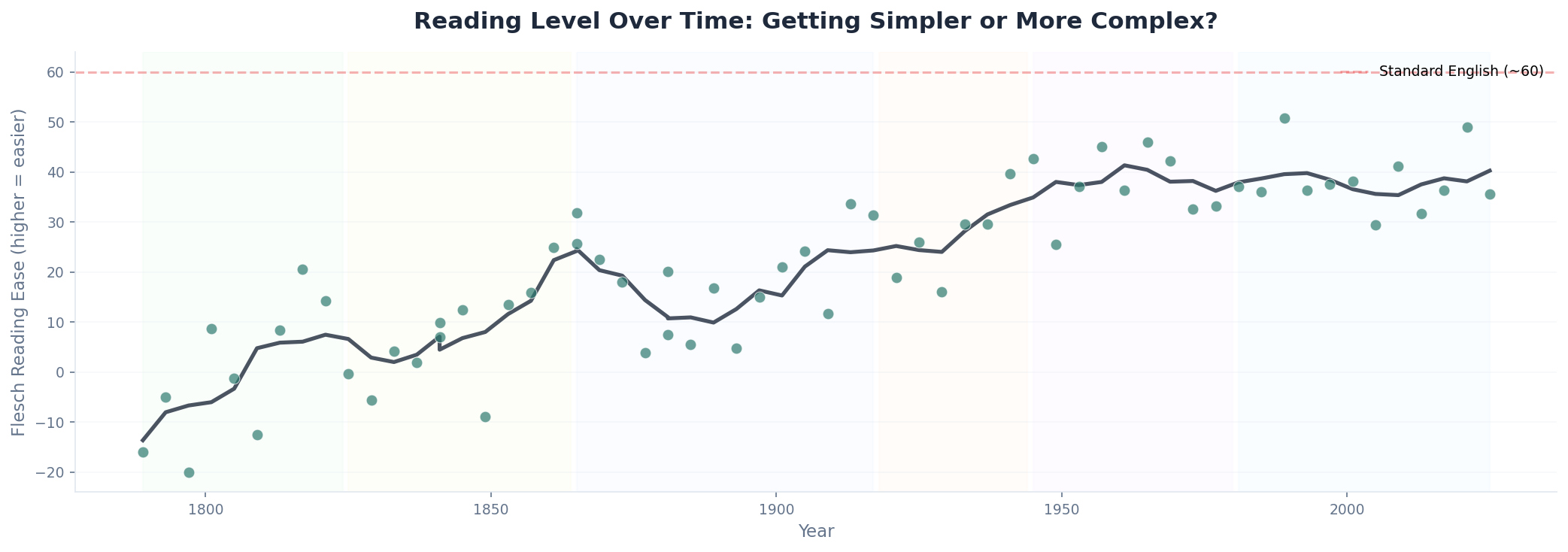
Reading level tells the same story from the other direction. The Flesch Reading Ease score—a higher score means easier to read—has climbed steadily over two centuries. The founders wrote at a level that today would be considered academic. Modern presidents use simpler, more accessible language for mass audiences. They aim for mass communication.
This is where it gets interesting. Track how often keywords appear—normalized per 1,000 words to control for speech length—and you can watch the American self-concept shift in real time.
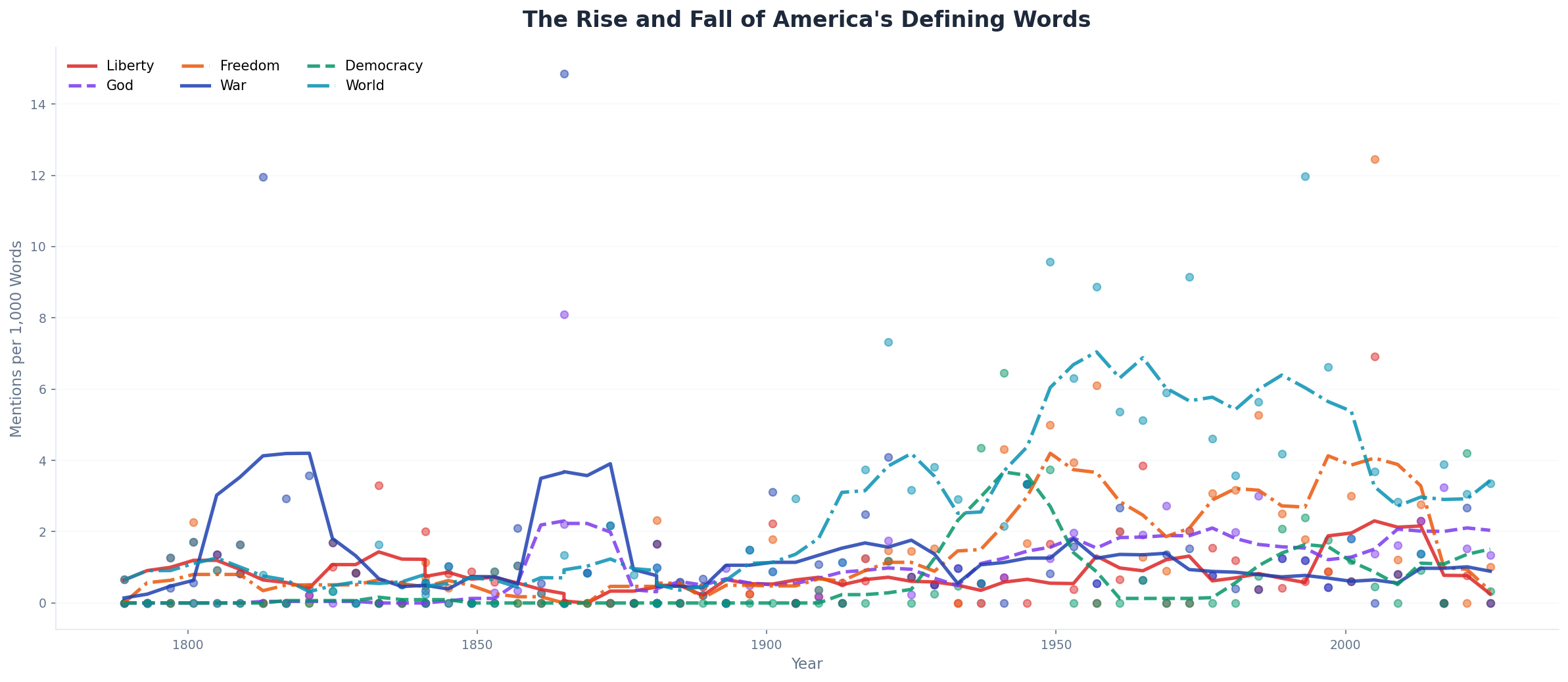
Liberty dominates the founding era. Washington, Jefferson, and Madison invoked it constantly—it was the revolution's rallying cry. But "liberty" begins a long, slow decline after the Civil War, replaced by a word that meant something subtly different: freedom. By the Cold War, "freedom" had eclipsed "liberty" entirely. The shift tracks a change in emphasis—from freedom from tyranny to freedom to participate in a global system.
War spikes predictably—1812, the Mexican War, the Civil War, both World Wars—but the word never fully disappears, even in peacetime. America has always defined itself partly against its conflicts. Democracy barely appears before the 20th century; the founders were suspicious of the word itself, preferring "republic." It rises with Wilson, peaks with FDR, and becomes central to Cold War rhetoric. World is nearly absent until the 20th century—America thought of itself as a continental power, not a global one, until the World Wars forced the shift.
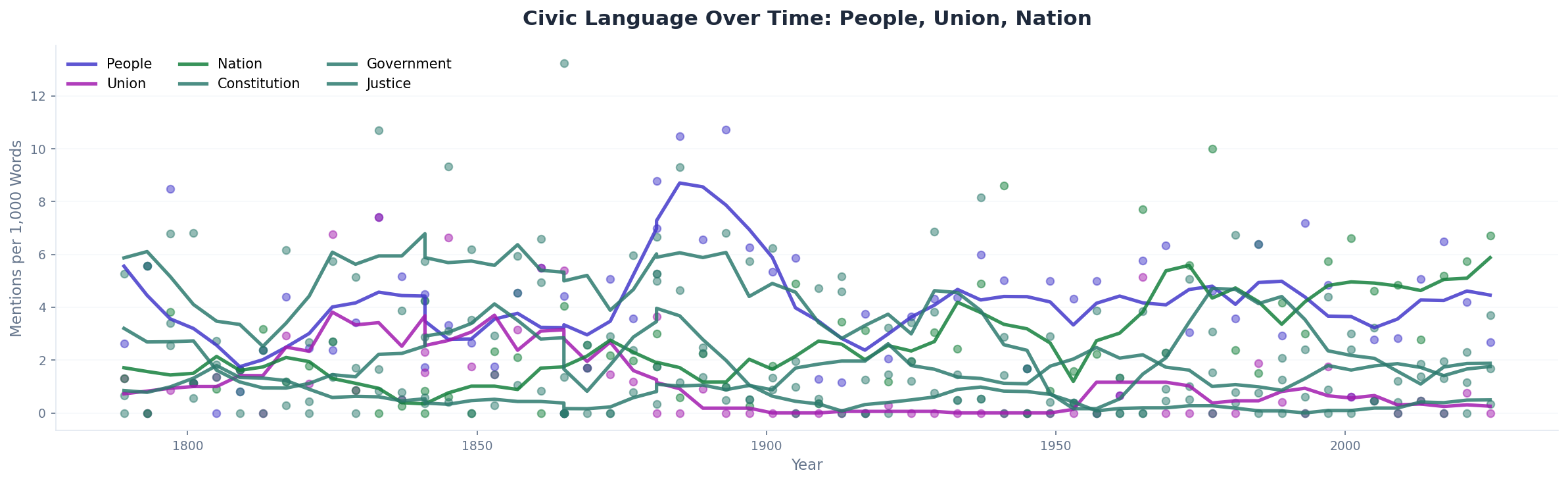
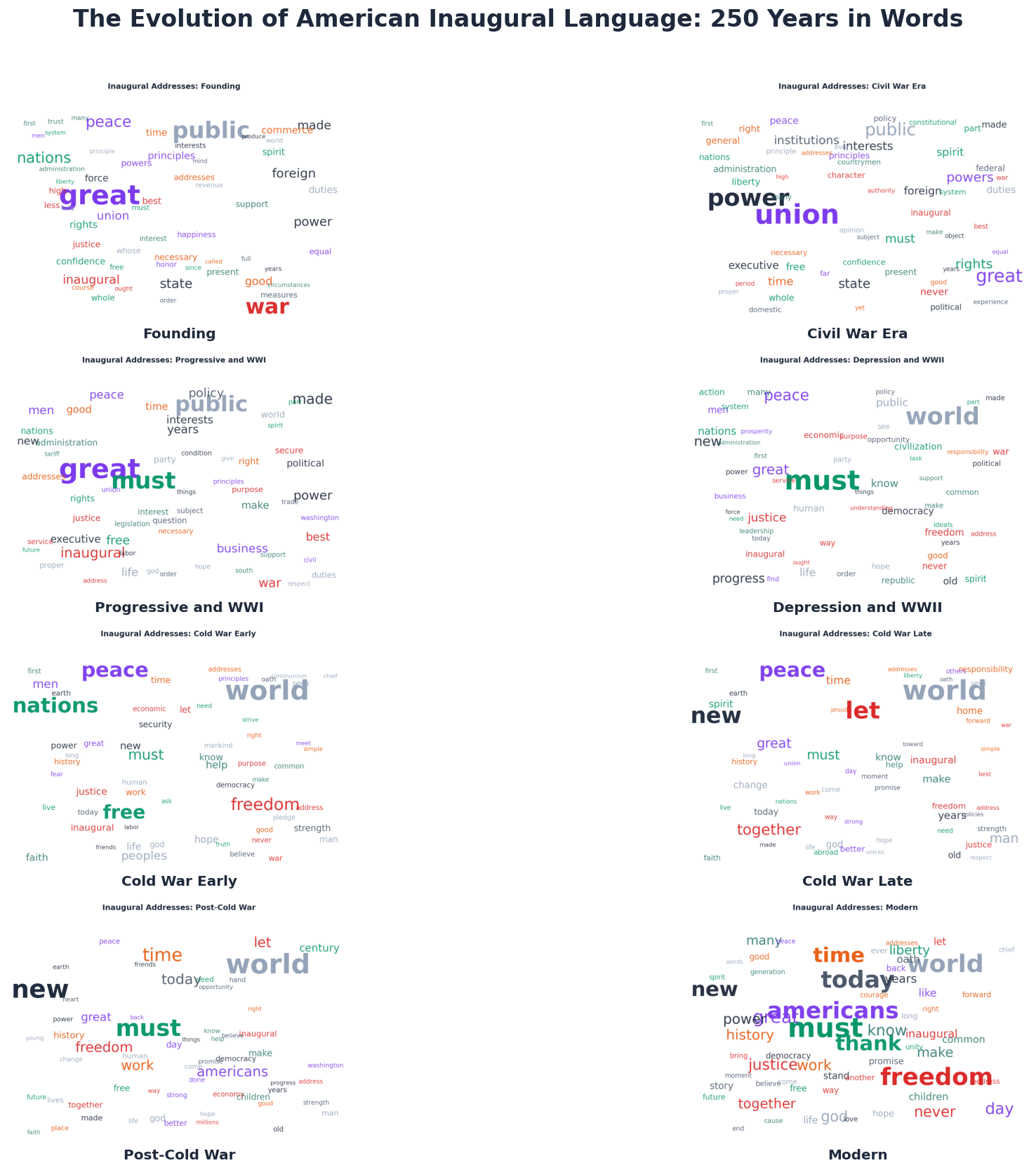
Aggregate all the words by era and the shifts become visual. The founding era is thick with liberty, union, principles, commerce. The Civil War era runs on union, states, rights, institutions. The Progressive era adds business, policy, public. By the Cold War, world, nations, peace, free, freedom dominate. And the modern era? Americans, today, justice, never, work, god — a language of domestic identity and moral purpose.
Here's the question that made me build all of this: if you strip away the dates and the names, can a machine feel the difference between a founding-era speech and a modern one? Is the language itself era-specific, or is political rhetoric timeless?
I built a neural network — a three-layer feedforward classifier — and fed it TF-IDF vectors (the 5,000 most informative unigrams and bigrams) from all 60 speeches. The task: predict which of 8 historical eras a speech belongs to, using nothing but its word frequencies. I evaluated with repeated stratified k-fold cross-validation: 100 folds, 1,500 held-out predictions, and each speech tested multiple times against models that had never seen it.
The model achieved 66.9% accuracy across all folds — nearly three times the 23.3% baseline of always guessing the majority class. That's strong evidence that American inaugural language has a real, measurable era signature. This suggests the model is capturing era-level linguistic patterns, though the dataset is small.
| Era | Sample Size | Accuracy |
|---|---|---|
| Founding (1789-1824) | 9 | 55.6% |
| Civil War Era (1825-1864) | 10 | 94.0% |
| Progressive & WWI (1865-1917) | 14 | 87.7% |
| Depression & WWII (1918-1944) | 6 | 15.3% |
| Cold War Early (1945-1962) | 5 | 64.8% |
| Cold War Late (1963-1980) | 4 | 8.0% |
| Post-Cold War (1981-2000) | 5 | 40.0% |
| Modern (2001-present) | 7 | 100.0% |
The pattern is revealing. The Civil War era is the easiest to identify—its language of union, states, confederacy, and constitution is unmistakable. The Modern era is perfectly classified—no other period uses words like thank, jobs, borders, bless the way 21st-century presidents do. But two eras collapse: Depression & WWII (15.3%) and Cold War Late (8.0%).
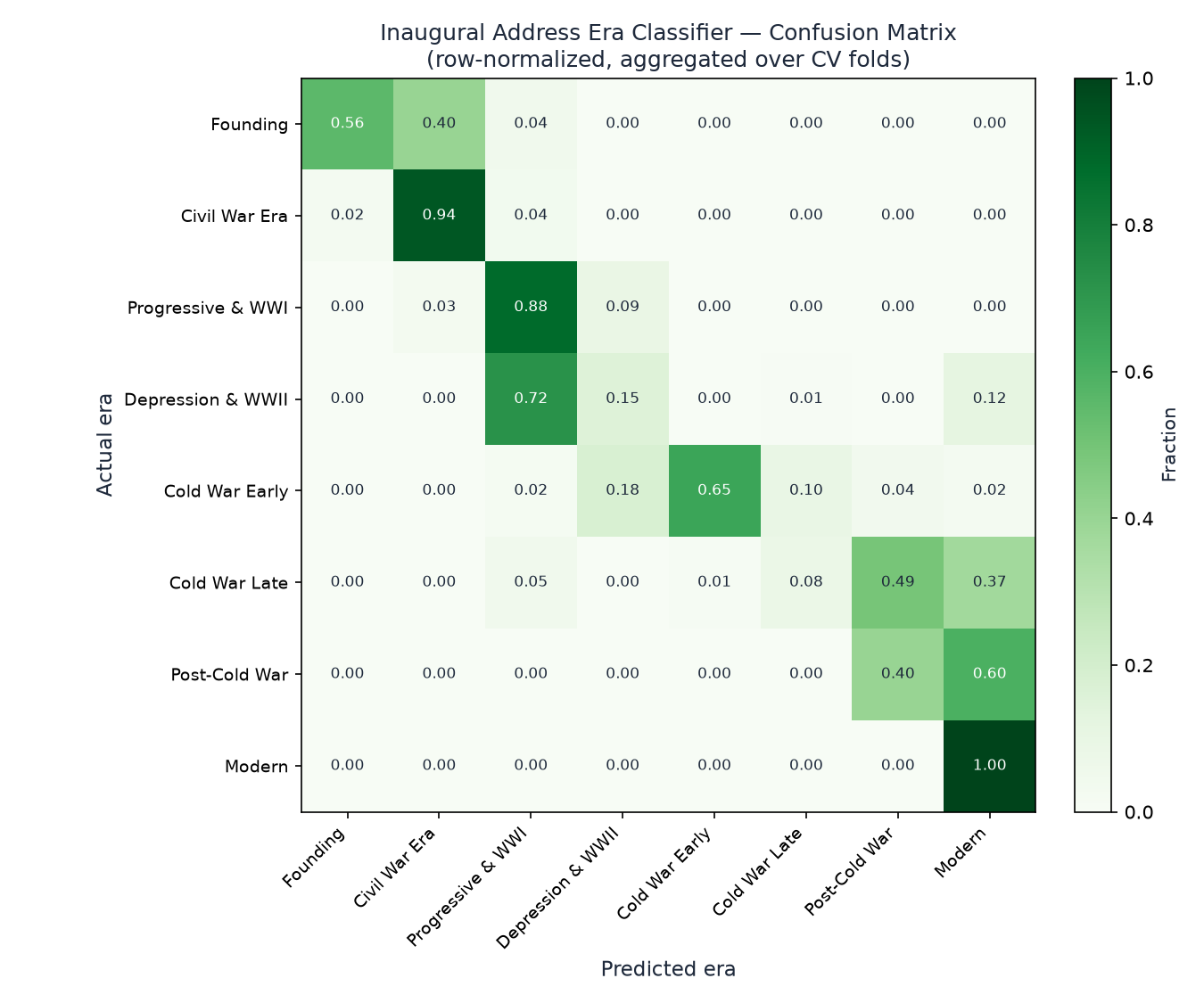
The most fascinating output isn't the accuracy — it's the failures. When the network is confused, it tells us something about the speech itself.
LBJ's 1965 inaugural was classified as Modern 100% of the time. Johnson's language — focused on the Great Society, civil rights, and American purpose — sounds more like a 21st-century address than a Cold War speech. He was, linguistically, ahead of his time.
FDR's 1941 third inaugural — the "Four Freedoms" speech—also reads as Modern. Roosevelt's global, rights-based language anticipated the post-war international order by a decade.
Coolidge (1925) and Hoover (1929) are classified as Progressive & WWI, not Depression & WWII. They are stylistically continuous with the era before them—the 1920s Republicans spoke like the 1900s Progressives. The linguistic break came with FDR.
Washington's second inaugural (1793) and Jefferson's first (1801) get pulled toward the Civil War era. The early-republic rhetorical register—formal, constitutional, state-focused—is one continuous linguistic zone that the model can't split at 1825.
By back-projecting the network's weights, we can see which words it associates with each era. The results are intuitive and sometimes surprising:
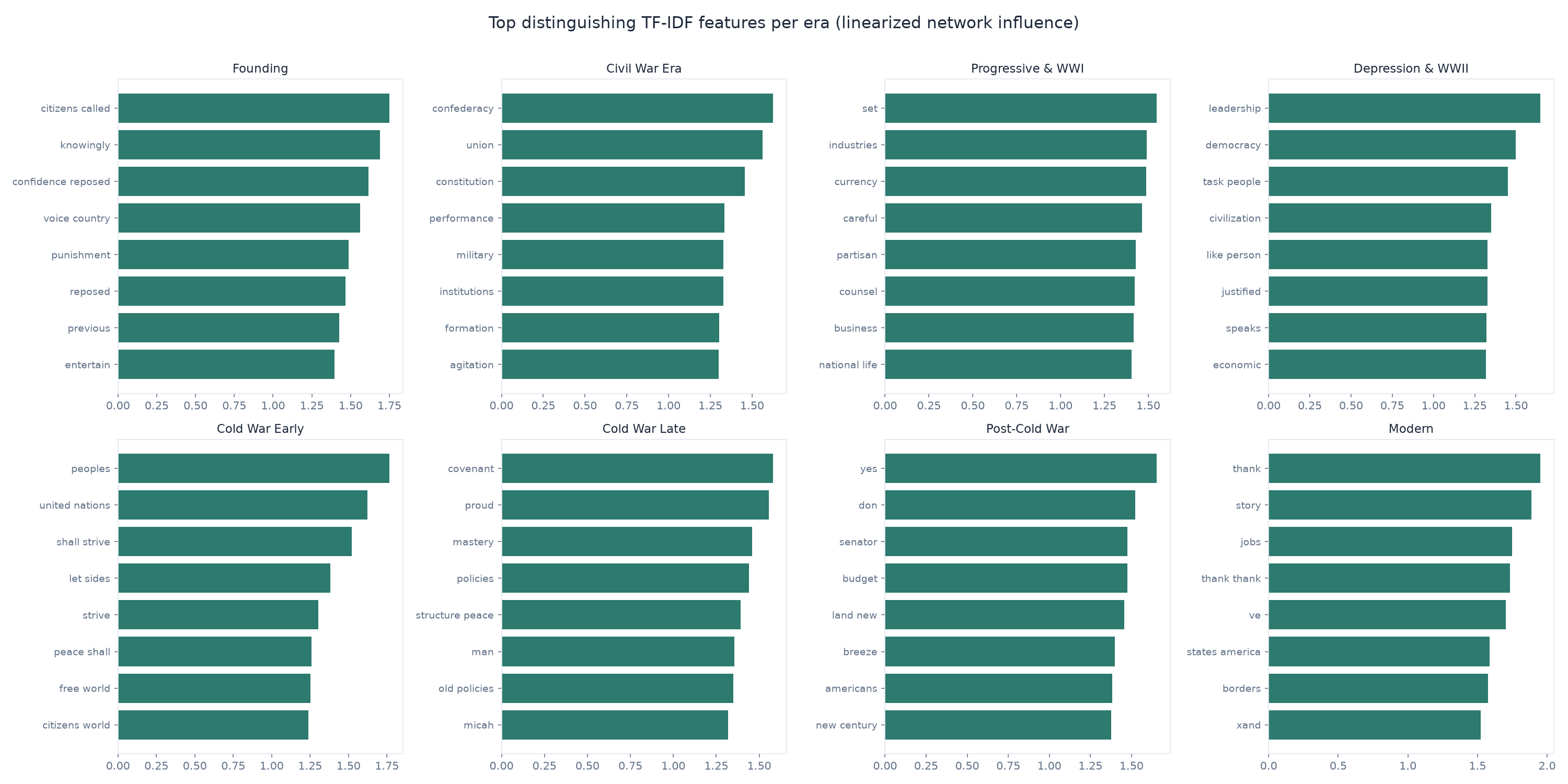
The Civil War era is defined by confederacy, union, constitution, states. Cold War Early by united nations, free world, communism. The Modern era by thank, jobs, god bless, make america, borders — a vocabulary that would have been alien to every president before Reagan.
The full classifier pipeline, from TF-IDF featurization through repeated stratified k-fold cross-validation:
import json, numpy as np, torch, torch.nn as nn
from collections import Counter
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import RepeatedStratifiedKFold
import matplotlib; matplotlib.use("Agg")
import matplotlib.pyplot as plt
SEED = 42
np.random.seed(SEED); torch.manual_seed(SEED)
ERA_NAMES = ["Founding","Civil War Era","Progressive & WWI",
"Depression & WWII","Cold War Early","Cold War Late",
"Post-Cold War","Modern"]
def era(y):
bounds = [1825,1865,1918,1945,1963,1981,2001]
for i, c in enumerate(bounds):
if y < c: return i
return 7
# Load corpus
with open("inaugural_addresses_clean.json") as f:
data = json.load(f)
data.sort(key=lambda d: d["year"])
texts = [d["text"] for d in data]
y = np.array([era(d["year"]) for d in data])
years = np.array([d["year"] for d in data])
N, NC = len(data), 8
# TF-IDF featurization: 5,000 unigrams + bigrams
vec = TfidfVectorizer(ngram_range=(1,2), max_features=5000,
min_df=1, stop_words="english")
X_all = vec.fit_transform(texts)
DIN = X_all.shape[1]
# Three-layer feedforward classifier
class Net(nn.Module):
def __init__(self, d_in, n_cls):
super().__init__()
self.net = nn.Sequential(
nn.Linear(d_in, 512), nn.ReLU(), nn.Dropout(0.3),
nn.Linear(512, 128), nn.ReLU(), nn.Dropout(0.2),
nn.Linear(128, n_cls))
def forward(self, x): return self.net(x)
device = "cuda" if torch.cuda.is_available() else "cpu"
def train_one(Xtr, ytr, epochs=120, seed=0):
torch.manual_seed(seed)
m = Net(DIN, NC).to(device)
opt = torch.optim.Adam(m.parameters(), lr=1e-3, weight_decay=1e-4)
lossf = nn.CrossEntropyLoss()
Xt = torch.tensor(Xtr, dtype=torch.float32, device=device)
yt = torch.tensor(ytr, dtype=torch.long, device=device)
m.train()
for ep in range(epochs):
opt.zero_grad()
loss = lossf(m(Xt), yt)
loss.backward(); opt.step()
return m
# Repeated stratified k-fold CV
# (k=4 because smallest class has 4 samples; 25 repeats = 100 folds)
K, REPS = 4, 25
rskf = RepeatedStratifiedKFold(n_splits=K, n_repeats=REPS, random_state=SEED)
Xd = X_all.toarray().astype(np.float32)
cm = np.zeros((NC, NC), dtype=float)
n_correct, n_total = 0, 0
for fold, (tr, te) in enumerate(rskf.split(Xd, y)):
m = train_one(Xd[tr], y[tr], epochs=120, seed=fold)
m.eval()
with torch.no_grad():
logits = m(torch.tensor(Xd[te], dtype=torch.float32, device=device))
pr = logits.argmax(1).cpu().numpy()
for j, idx in enumerate(te):
cm[y[idx], pr[j]] += 1
n_correct += (pr == y[te]).sum()
n_total += len(te)
overall_acc = n_correct / n_total
print(f"CV accuracy: {overall_acc:.1%} over {K*REPS} folds")
print(f"Baseline: {max(Counter(y).values())/N:.1%}")Everything above was computed end-to-end on home hardware. Here's the architecture of the full pipeline:
Two hundred and fifty years ago, America began with a sentence it has spent generations trying to live up to: that all people are created equal. Every four years, a president stands up and tells the country what it is. The words change. “Liberty” becomes “freedom.” “Union” becomes “world.” “Commerce” becomes “economy” becomes “jobs.” But the act is the same: America talking to itself about what America means.
This entire tribute — the corpus, the charts, the word clouds, the neural network, the film — was computed on home hardware on the nation's 250th birthday. Every word of every inaugural address belongs to the public domain. The analysis is ours (me and my agent). The story is America's.
July 4, 2026
Thoughts and essays, published with Yokush. See more posts
 Siddharth11
Siddharth11 Siddharth30
Siddharth30 Siddharth00
Siddharth00
Comments 0